How we turned unachievable requirements to an acceptance of a DevOps methodology by realizing that traditional methods would not allow us to work efficiently enough and showing that to the rest of the organisation.
Our system would have to run at 99,99% was the new message from our business. That number in itself does not give you a good understanding of the challenge; it’s better expressed as a maximum of 53 minutes of downtime – per year.
When this was presented to the team they responded flatly that it would be impossible.
“Just making an upgrade to the database means taking down the servers for more than an hour”
Looking back at the last outage where we sent logs back and forth between us and the database team for days 99,99% did not seem likely. It became clear that if we were to achieve our uptime goal we would need to be able to to zero downtime deployments and cut as much of our dependencies on other systems as possible. To do that we needed full control over the infrastructure.
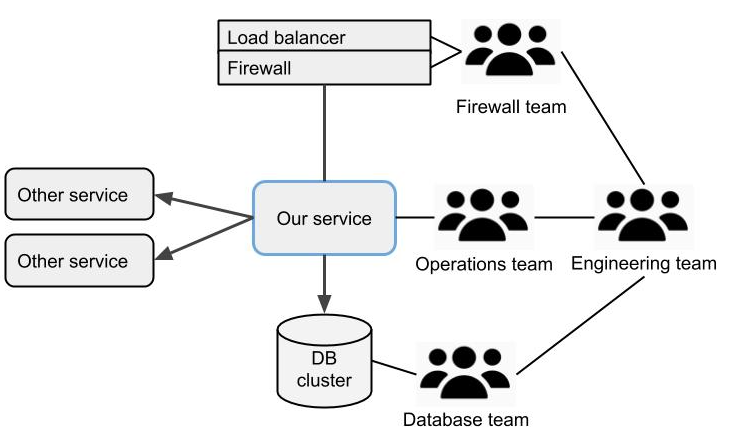
The aim was going to the cloud and to bring the infrastructure with us. Unfortunately our policies at the time did no allow any of our products to be cloud hosted and the IT department was a long way from approaching cloud infrastructure, having just invested loads in a brand new data centre. When we presented our plan to the business side they accepted that we did not have much other choice and when we both pressed the issue the resistance gave way given that we took full responsibility for operations.
“There is no in house competence on cloud so then you are on your own”
We spent six months building infrastructure and functionality to cut dependencies and launched our service with our own database instance, load balancer etc.
Our DevOps journey had begun.
Key takeaways
Align with business objectives when suggesting a change to DevOps methodology
If you business team sees a need for improvements on operational aspects or the rollout speed for new features it’s a golden opportunity to team up and push for DevOps towards the rest of the organisation.
It is often hard to get acceptance for a major change like, completely moving responsibility from one department to another, and it’s crucial that you can show how the change will achieve certain business objectives. Therefore it’s advisable to first have the discussion with the people who are closest to the business results and are the ones who have the most to gain from this.
Also, finding arguments before a major discussion is also important. Being able to roll back a change within minutes is usually a huge plus also from a conservative standpoint.
Analyze where your current pain points are
Do the majority of your problems occur during deployment or is it certain dependencies you have? If you don’t have a clear picture of root causes then your first step maybe should be to map those out so that you know where to start. In our case we could see that dependencies and time spent waiting for information between teams during troubleshooting was causing the brunt of our downtime.
The first league as a DevOps team
Once we had built infrastructure and functionality allowing our service to function on it’s own in a cloud environment we almost immediately saw an improvement in uptime but we could also still see deployment issues at times.
First we had issues with configuration files that hadn’t been updated in the production environment in correspondence with our test environment and then there was other inconsistencies creating problems.
We also found that we sometimes were blissfully unaware of problems in the production environment while happily working with something else. Only when these problems became critical would an alert trigger – or worse, an escalated support ticket, reach us. Sometimes we found that a whole host instance had stopped working while no alarms went of since it was still ‘online’ and the other redundant host kept serving requests.
We started tackling the deployment issues and made sure that no host configuration changes could be made manually. Only with our deployment scripts could anyone change anything and since our build server only worked through our version control we had to check in any configuration changes along with the code.
Now we observed a higher success rate in deployments – every change we made to the environment to get certain code to work would always follow that code to every environment and we could also easily roll back when something did go wrong.
Secondly, we started using our big screen used for our standups to show graphs of the number of http requests and errors in our service along with host health details (CPU level, memory consumption etc) and with this we could immediately see when something started going wrong. We were surprised of how many non critical issues that came and went (previously unnoticed) and started filling our backlog with fixes these.
One of the things we observed was that unresponsive hosts were sometimes triggered by CPU spikes. This caused a major headache for us and our team had to get online to restart servers on nights and weekends (we were on our own remember).
While finding the root cause and making a fix for it (this took way longer than expected) we connected our cloud monitoring tools with a small service designed to gracefully restart a host. By choosing our alerts carefully we could now make any host restart if it ran out of resources or for any other reason became unresponsive. With our services now self healing we could rest more peacefully.
Key takeaways
By automating our configuration management we secured reproducibility for all environments – this is a key factor to enable continuous deployment.
By increasing our observability we could respond to problems proactively and improve our service based on data from the field. Without knowing it at the time we were now more of a data driven development team.
The overall conclusion of this is that our team started finding ways to automate everything that felt tedious, error prone or energy consuming and without anyone asking for it we improved the service robustness.
The challenges
After running our service ourselves for some time we started to see that what we were doing was not actually DevOps but rather a kind of NoOps and that doing so puts a certain strain on a team. Every time something happened we had to immediately fix it, even if it was off hours and our team was too small to get a functioning on call rotation in place. Later we got a 24/7 monitoring team but they could only forward incidents to our team which meant we still had to stay on alert at all times.