There has been considerable interest in the DDDSample application on the Swedish DDD user group mailing list – people are scrutinizing the code, asking questions and raising concerns. This last week has been mostly about layers and packages, and I think this blog is a good forum to provide a little background and explain the rationale behind how the sample application is structured.
 There has been considerable interest in the DDDSampleapplication on the Swedish DDD user group mailing list – people are scrutinizing the code, asking questions and raising concerns. This last week has been mostly about layers and packages, and I think this blog is a good forum to provide a little background and explain the rationale behind how the sample application is structured.
There has been considerable interest in the DDDSampleapplication on the Swedish DDD user group mailing list – people are scrutinizing the code, asking questions and raising concerns. This last week has been mostly about layers and packages, and I think this blog is a good forum to provide a little background and explain the rationale behind how the sample application is structured.
When we first started working on the application, we used a fairly standard layering with a web user interface layer, a service layer with interfaces, implementations, transaction demarcation and so on, and a repository layer for persistence, implemented in Hibernate (roughly matching the DAO layer found in most applications). These layers all resided in their own package hirearchy. In addition to that, the domain model had its own package, although it wasn’t a layer in the usual sense – it was used by several other layers, but calls did not pass through the domain model on to some other layer. This suited us well for the time being, since there were many other aspects of the application that required our immediate attention.
As the application grew more mature, we began looking at how the structure of the application could illustrate important DDD concepts such as aggregates and isolating the domain. In his book, Eric Evans uses this diagram when talking about layered archicture:
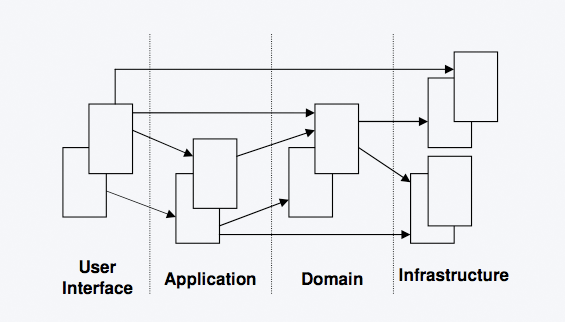
By far the most important layer is the domain layer, so we decided to take a closer look at the contents of our domain layer and the domain package. A pretty obvious decision was to place each aggregate in its own subpackage below domain, so we had domain.cargo, domain.handling and so on. Deciding which services were domain services and which were application services was harder, but we settled for a separation where domain services performed tasks that you could talk about with a domain expert, using the ubiquitous language. Signatures consisted completely of domain model types. In some cases, it was natural to place the interface of a domain service in the domain layer, but the implementation elsewhere.
But the decision that would turn out to be the most controversial was placing the repository definitions (i.e. the interfaces) in the domain layer, alongside the aggregate root for which it was used to retrieve, store and search. The concept of an aggregate root is closely linked to that of a repository: all access to an aggregate is through the root, so consequently the repository works with aggregate roots, and there is one repository per aggregate root (and thus per aggregate). Also, repositories are expressed in the ubiquitous language.
At this point our domain layer consisted of the domain model, separated into aggregates, domain services and one repository per aggregate, which we felt pretty good about (and still do). It expressed many important DDD concepts in a clear way, and it was slightly unorthodox compared to many mainstream designs. All this was located under the domain package.
The question of what to do with the rest of the application remained. The other three layers are not as interesting from a DDD perspective, so we decided not to pursue the effort of organizing the rest of the code into per-layer-package hierarchies, but instead separate it from the domain package and organize it by a combination of technology and use cases.
We did however consciously include two very different approaches to user interface exposure. The tracking web interface, which runs in the same JVM as the main application, is the low-overhead-thight-coupling way of doing it (in terms of layers and lines of code), where the MVC controller acts as application layer and calls the domain layer repository directly. The tracked cargo is thinly wrapped in the view rendering phase to make it easier to work with in a JSP EL environment.
The booking web interface on the other hand can run in a different JVM and works against an RMI facade on top of the domain layer, passing custom DTOs back and forth. The point is that we don’t generally recommend a mandatory, slavishly delegating application layer between the presentation and the domain layers. Sometimes the controller in the MVC layer can play the part of application just as well. Another important point here is that you should always shield the domain model objects from presentation requirements, and DTOs or a thin presentation wrapper and so on are good options for doing that.
The top level package for all non-domain-layer code was named application, which turned out to be a bad idea (mine) since the name coincided with one the the layers in the picture above. For the record, the rationale behind it was “application” as in “computer program”, i.e. everything about the code that wasn’t part of the domain. A better name would have been something like nondomain or even other.
This problem immediately became apparent when I presented the application to the New York DDD User Group, so a separate ui package was extracted for the web MVC controllers and supporting code. This actually turned out to make matters slightly worse, since we now had top-level packages with names matching three out of the four layers in the DDD layer model, immediatly leading people to ask for the missing infrastructure package. The discussions on the mailing list and other forums helped us realize that there is a need for an explicit infrastructure package, so the next version of DDDSample will include such a package containing the parts that we consider to be part of the infrastructure layer.
It appears from the discussions on the Swedish user group mailing list that many people think of the infrastructure as being identical to the persistence aspect (the database and the O/R mapper), but we have a wider definition of infrastructure which also includes messaging, scheduling, thread pools, the Spring container, the servlet container and external services such as mail senders and in our case the routing team’s graph path finding service.
Looking at the picture above, the arrows between the layers actually illustrate the point quite well: the presentation, service and domain layers all work with the infrastructure layer, but it’s important to realize that it doesn’t mean that you should execute SQL statements in your JSP pages, but rather that each layer interacts with some part of the infrastructure. Also, the infrastructure layer can be used for passing asynchronous messages between layers.
In general, we consider code and configuration files that we write in order to hook into the infrastructure to be part of the infrastructure layer – Hibernate repository implementations, HBM mapping files, Spring context definition files, the RoutingService implementation and so on. Sometimes the distinction is harder to make, such as having an application service implement the JMS MessageListener interface to act message-driven.
As a rule of thumb, never state rules of thumb when it comes to software development. But if I were to do that anyway, I’d say that the infrastructure layer should be completely separable from the rest of the application by stubbing out external services, implementing persistence in-memory, and using synchronous calls or simple threads for messaging.
One reply on “On layering in DDDSample”
> 10 years later I found this to be valuable resource (short but valuable) for demistiying hexagonal architecture + DDD. This can be considered as pioneers effort in that direction. I have read many books, watched many DDD tutorials and even went to DDD immersion in Portland, but I am referring over an over again to this original Cargo shipping example.